
 These ideas and suggestions are from my experience with IT incidents solving problems with complicated and interdependent systems. In most cases accurate, timely and safe finger pointing was the key to getting the problem sorted. There are a few thing that need to be in place before this can happen. I’ll cover what I’ve learned fixing issues with colleagues.
These ideas and suggestions are from my experience with IT incidents solving problems with complicated and interdependent systems. In most cases accurate, timely and safe finger pointing was the key to getting the problem sorted. There are a few thing that need to be in place before this can happen. I’ll cover what I’ve learned fixing issues with colleagues.
I’ll cover
- some ideas for solutions to the problems we have working together
- issues with experts and non experts
- a framework for a team to solve problems under pressure
- a way to share and collaborate across knowledge silos
IT problems with complicated Systems
Hard to fix problems are usually the ones no-one expected. Problems we expect have planned and tested responses. Often we design them out. The problems that are left have fell down the gaps in our shared knowledge.
The way we build things
The way we build things can make them hard to fix.
For example, if there are three specialist teams building your application, you’ll get an application with three parts. You may design it this way, or you may get a mirror of whatever your organization structure is. This Conway’s Law in Action.
Due to Conway’s Law, the architecture of your IT system may be decided by the division of work between teams, due to knowledge silos or desire for clarity of management structure, rather than optimizing running the finished system.
Solutions to problems are often where two knowledge silos meet and the silo locations were there before any code was written.
Hey! We need silos!
We can say that knowledge silos are bad. We need to get rid of them. The frustration with some forms of silo behaviour is understandable. For complicated systems, knowledge silos are inevitable. No one can know how everything works. Unfortunately Fixing Silos by bridging them, or breaking them down them creates more problems. The bridges and new structures become the new problem sites. It’s inevitable we’re going to have silos where deep technical expertise is required. The best we can do choose where these silos are, why they exist and how we manage the boundaries.
Who is in the room
Things have gone wrong, and people are in a room looking for a solution. Some are Subject Matter Experts, others may be responsible for teams involved, for communication or as customer advocates. There is likely to be senior management who is being asked by the CIO how long until it’s fixed.
To fix the problem quickly, the composition of people in the room is vital. You need the people who designed the system, configured it, wrote the tests and those who run it. There may be knowledge silos across teams here.
You also need someone who understands the big picture but not the details. This role is vital to ask fresh and simple question that experts may not see.
You also need someone to get extra resources you’ll need, book rooms, write communications, and document the decisions that were made, and approve changes that are made to mitigate and investigate the problem.
More Silo Dangers
In a high pressure situation, a lack of psychological safety makes people avoid suggesting diagnosis if they risk their opinion and their past work being judged.
Even where safety exists in a team, it may not exist between silos.
It may be career limiting in an organization to be seen to be the cause of an issue where learning is not valued.
Under pressure people gravitate to general, rather than technical skills (http://bit.ly/AllspawThesis), and under pressure we may defend our silo territory before looking to solve the issue.
Group Problem Solving Anti Pattern #1 Beginner > Expert
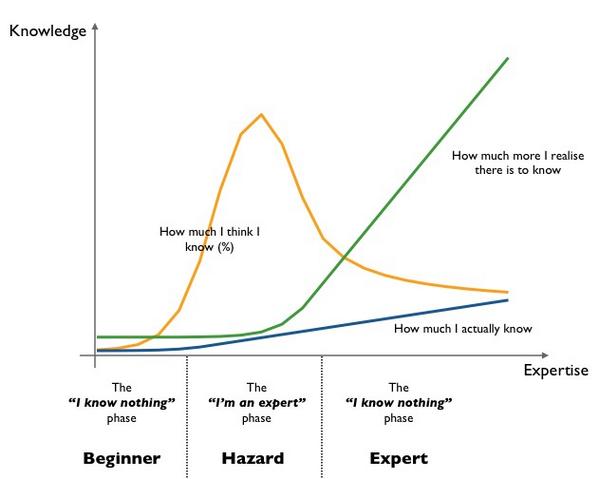
from @swardley
The more you know about something, the more you know you don’t know. Simon Wardley joked about this and seemed to hit on some visceral truth. There seems to be more than a shred of truth in this, as beginners are often more certain than experts.
People like to save face. Without work, cross silo meetings are not a safe spaces, being wrong is bad, being responsible for the system at fault may be worse.
Group Problem Solving Anti Patterns #2 – Hippos
Perhaps someone senior (the Hippo, Highest Paid Person in the rOom) has heard about X. That’s what they heard broke last time. They’d really like you check that right now. Maybe the person responsible for X puts forward a strong case why it definitely isn’t X. The defense works but the barriers are now up, and there is a round of finger pointing until someone risks losing an eye.
Worse, someone technical, knowledgeable and dilligent may reply “well I suppose it could be X” (see Anti Pattern 1). And a group goes off to look at X. (Pro tip : It’s probably not X).
Group Problem Solving Anti Pattern #3 Experts are also not enough
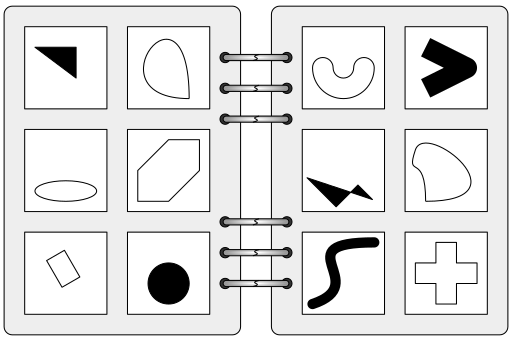
A Bongard Problem. What is the difference between all the images on the left, and all the images on the right? This sort of problem has all the information you need. You’re looking for patterns.
Experts are rarely enough if the incident was caused by something unexpected. Experts know what to expect and what they have seen before. The problems of being an expert in an open system, where something new has gone wrong has been covered in my post about Bongard Problems. These problems, where you have two sets of information – before and after – are very similar to IT problems. You’ve got two situations, and you’re looking for the difference that makes a difference. If you’re pattern matching things you’ve seen before, and you’re the expert so you’re not expected to be wrong, new problems can be hard to find.
Someone is required who can ask questions and doesn’t let what they already think they know get in the way. Someone who doesn’t have expert knowledge will find this easiest.
We need a facilitated solution
Someone in the room needs to step up and facilitate the group. It may be that everyone takes one step back and you end up being in charge.
Whoever facilitates need to make sure there is
An Incident framework to follow
What should we do, who should do it, what we do next. This is what goes in the ITIL service management box ‘fix the broken thing’. Ideally there is someone who books room, arranges test areas and gets any hardware or software required for the team fixing the problem.
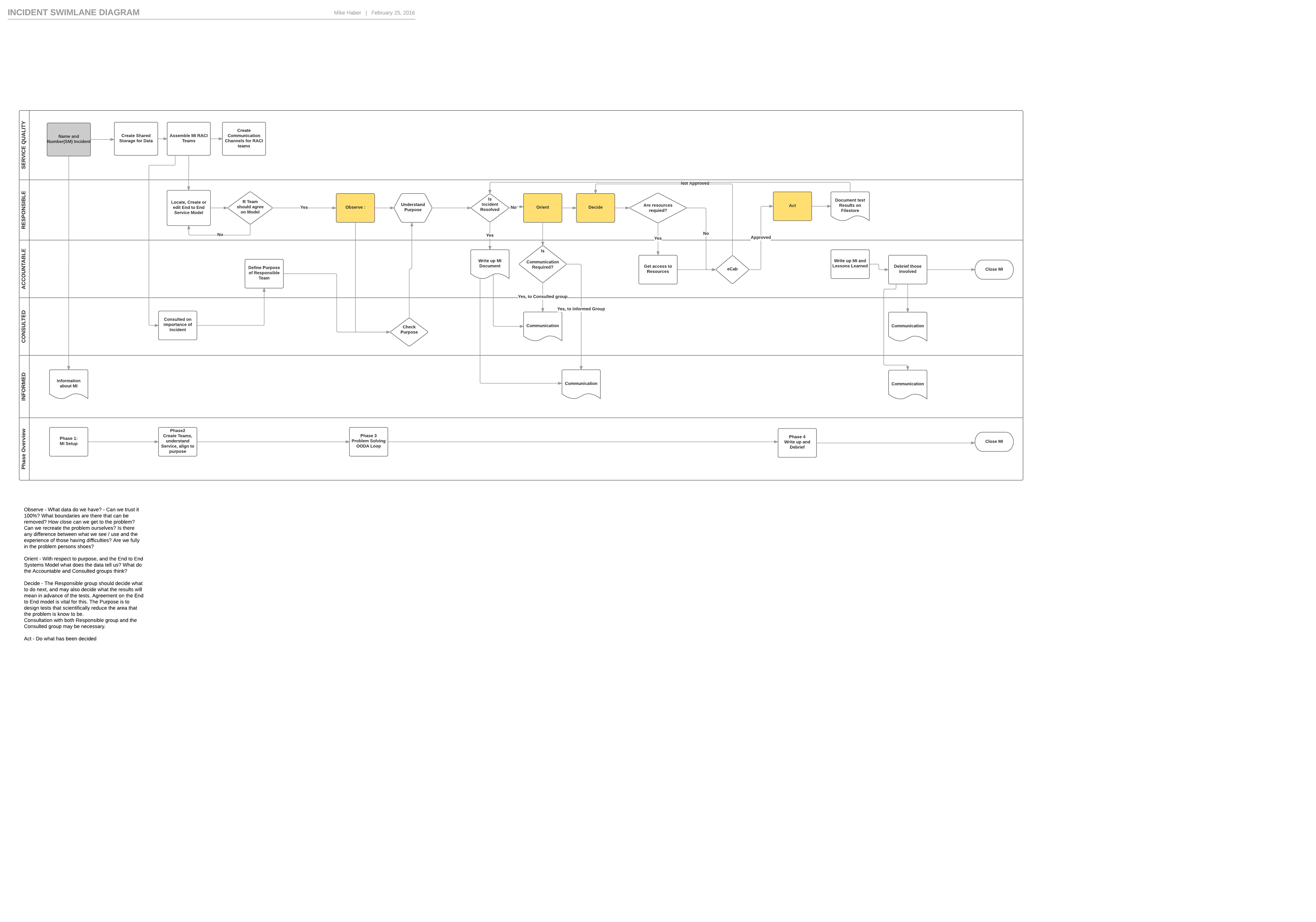
A example P1 incident process to follow. This can be improved.
A overall End to End systems map
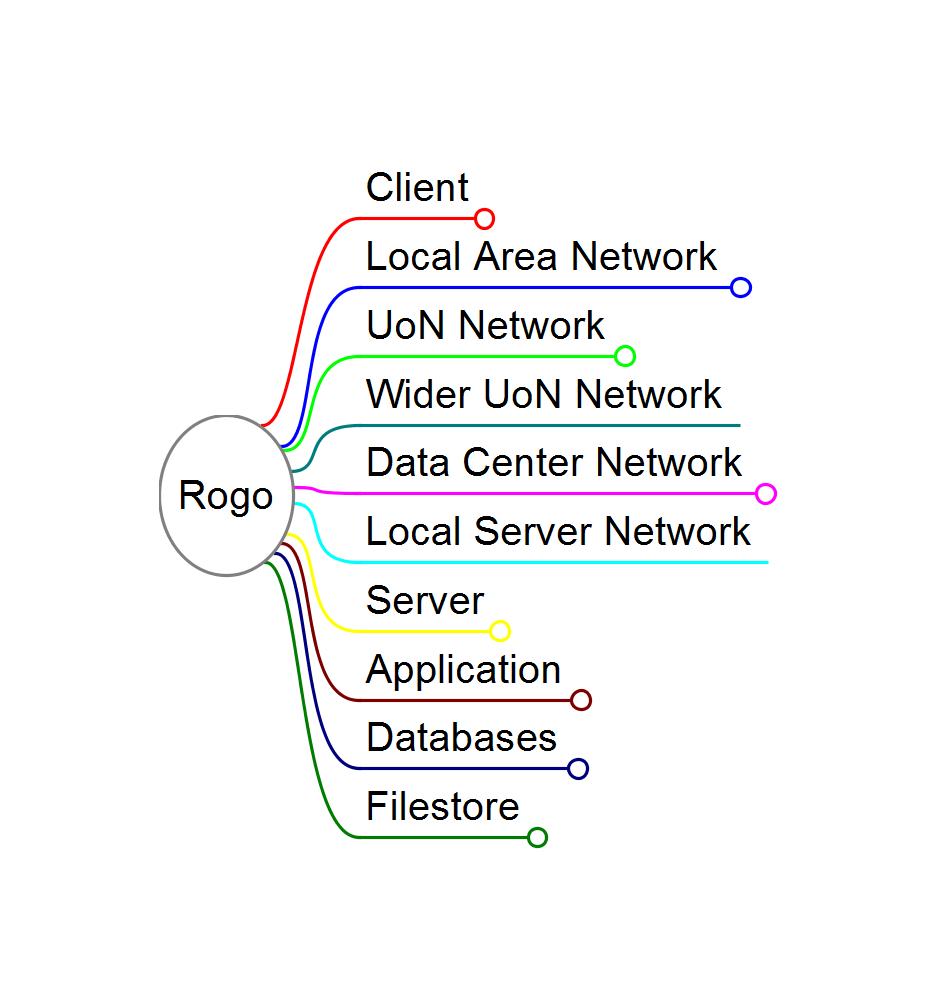
Very Simple Mind Map of a Client Server Application. The detail is hidden, and would go left to right. Top to bottom goes from the client to datacenter, and into the components.
This is not the architecture model, or a solution design. Those won’t do what we want.
The purpose of this map is to help solve problems, so it’s different from the documents produced in architecture and design. It’s owned by the DevOps or IT Operations & Development teams. It is a map of how all the bits fit together in a journey to get your users needs met. You can point at it, and everyone one in the room knows what your talking about. It allows fora shared mental model.
The key to the map, is that everyone agrees that it is correct, and it’s changed to reflect any new information with information being added to the map in the correct place. When people talk about the problem they can point to the map to show the area they are talking about. This can save a load of time and misunderstanding. It also mean that large areas can be ruled out, meaning that Anti Pattern #2 can be avoided.
We can then ask better questions, and make better decisions as we’re talking about the same thing.
We’re pointing at this map, not at each other! We ask questions about the map, everyone has a shared model of the system. We make better decisions.
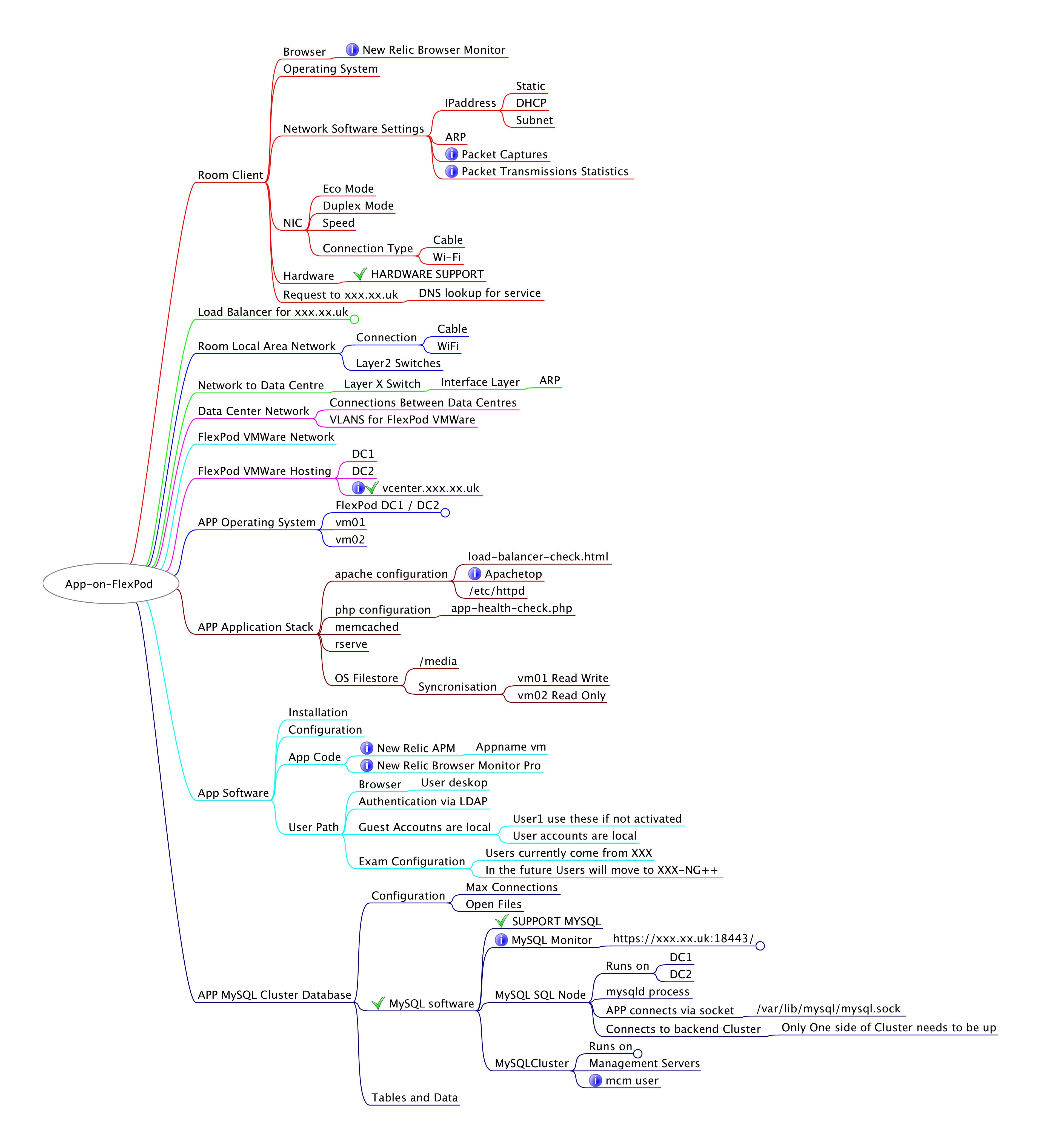
This map was used to pinpoint a very hard to find problem that would occur for users about once every few day of constant use – and would “fix itself” after less than 5 mins.
Observe, Orient, Decide, Act
“What we do next” to find the solution can be answered by John Boyd. OODA, the US Military Engagement Strategy for complex fast changing situations is also great for approaching IT problems.
For other problem solving methodologies see Brendan Greggs excellent site.
OODA is a fast decision making loop. If you need to have an Emergency Change Approval Board before each Act, decide who’s on this and make it happen quickly if you want things fixed. This is a feedback loop that can run really quickly. Have the right people in place.
Observe
What do we know? What is instrumented? Is there information from users? How much do we trust the data? This information will have been collected and added to your map. Show what information we know where.
Orient
As an Incident Team, discuss what does this data mean? Where does it suggest the problem may be? What do we now know, and with what certainty?
You’ve probably just run and test, and you should already know what the results mean, but it’s likely you also have new data from other sources too.
Decide
Decide what test to run next. Everyone needs to agree what the potential results of the test means. Ideally the next test will rule out the largest part of the End to End map possible.
Using the End to End diagram, understand what the data may be suggesting. When evaluating proposed actions as “What is ruled out if the results are X, what is rules out if the result are Y”. Ideally you’ll design tests that give X or Y.
You need to decide as a Team what the results mean before the test is done. What the results mean should be visible on the End to End diagram. For example a test should allow you to rule out parts of the system.
Every test goes through this. So if the Highest Paid Person in the rOom thinks you should find what is being tested on the End to end diagram, and the things that can be learned from the results are discusses.
Act
Run and document the test and results.
Where do the fingers point now?
Instead of pointing fingers at each other, the Incident Resolution Team are pointing fingers at the End to End Diagram, and asking questions like “what would reconfiguring this tell us” or “We could replace this component to rule out all of this part of the diagram”.
New ideas can be quickly evaluated, and extra detail is quick and easy to add where it is required.
We can ask better questions and make better decisions. When we are asked why, we can point at a map, rather than a person. That’s got to be better.







 There had to be some passionate conversations between factory managers, and executives at Mercedes-Benz with this one. Replacing some robots with people has caused all sort of problems. If the factories are quite new, and were built for automation they probably don’t have many toilets near the factory floor. Or a large car park, or canteen. Robots don’t drive to work, and need to eat. Factory managers will take personal and professional pride in running efficient operations and automation has made cars affordable, reliable and available.
There had to be some passionate conversations between factory managers, and executives at Mercedes-Benz with this one. Replacing some robots with people has caused all sort of problems. If the factories are quite new, and were built for automation they probably don’t have many toilets near the factory floor. Or a large car park, or canteen. Robots don’t drive to work, and need to eat. Factory managers will take personal and professional pride in running efficient operations and automation has made cars affordable, reliable and available.
{kind=link}